0x00 前言
还是得先单独系统得学习学习java的反序列化的知识,不然研究很多东西还是会有些一头雾水。
0x01 什么是java的序列化和反序列化?
正如前面学习rmi时我所提到的,jvm虚拟机之间需要传递的内容是一个个java对象,而对象只是java里面的概念,而我们正常通信传输的形式只能是二进制数据,如何将java对象变为可以传输的字节流就是关于序列化的问题了。而反序列化,则是当传输的数据到达另一端后,如何把字节序列恢复java对象的过程。当然除了通信,序列化和反序列化也会被应用在对象的持久化存储中。
一个对象要想序列化成功,需要同时满足下面两个条件:
- 该类必须实现 java.io.Serializable 接口。
- 该类的所有属性必须是可序列化的。如果有一个属性不是可序列化的,则该属性必须注明是短暂的。
其中的”短暂“是指关键字
transient,它可以用来修饰类的成员变量(属性)。当一个属性被声明为transient时,该属性将被标记为短暂的,意味着在对象进行序列化时,该属性的值不会被持久化保存。这一点不是很重要,我们不必太过在意。另外,如果你想知道一个 Java 标准类是否是可序列化的,可以通过查看该类的文档,查看该类有没有实现 java.io.Serializable接口。
我们先来一个简单的示例,还是以前使用的User类,该类实现java.io.Serializable类:
package com.Anchor;
import java.io.Serializable;
public class User implements Serializable {
private String name;
private Integer age;
public User() {
}
private User(String name) {
this.name = name;
}
public User(String name, Integer age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
System.out.println(this.getName());
}
public Integer getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "User [name=" + name + ", age=" + age + "]";
}
}
然后来个SerializeDemo类将其序列化为二进制文件,首先要创建OutputStream对象,再将其封装在一个ObjectOutputStream对象内,接着只需调用writeObject()即可将对象序列化,并将其发送给OutputStream(对象是基于字节的,因此要使用OutputStream来继承层次结构)。
package com.Anchor;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
public class SerializeDemo {
public static void main(String[] args) {
User user = new User();
user.setName("anch0r");
user.setAge(123);
try{
//打开一个文件输入流 FIleOutputStream
FileOutputStream fileOut = new FileOutputStream("G:\\Desktop:\\user1.db");
//建立对象输入流,将这个FIleOutputStream封装到ObjectOutputStream中
ObjectOutputStream out = new ObjectOutputStream(fileOut);
//调用writeObject方法,序列化对象到文件user1.db中
out.writeObject(user);
out.close();
fileOut.close();
System.out.println("Serialized data is saved successfully!");
}catch (IOException i)
{
i.printStackTrace();
}
}
}
运行后,在相应路径下生成了一个user1.db的二进制文件,将其拖入到编辑器中查看内容:

我们从最右边的字符显示中可以依稀看到该序列化数据的一些信息,比如全限定类名 com.Anchor.User、属性名以及对应的数据类型等等,但这些都不是重点,注意看我左上角框出的那串十六进制数字:ACED 0005, ACED是魔术数字(STREAM_MAGIC),而0005是版本号,代表这里使用了序列化协议,从这里可以判断保存的内容是否为序列化数据。(这是在黑盒挖掘反序列化漏洞很重要的一个特征)
下面再编写个DeSerializeDemo将对象从字节序列中读到内存中,并打印相应的信息。对应地,这里首先要创建InputStream对象,再将其封装在一个ObjectInputStream对象内,接着只需调用readObject()即可将文件中的内容反序列化,要实例化一个user对象用来接收反序列化的结果。
package com.Anchor;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
public class DeSerializeDemo {
public static void main(String[] args) {
User user1 = null;
try{
FileInputStream fileIn = new FileInputStream("G:\\Desktop\\user1.db");
ObjectInputStream in = new ObjectInputStream(fileIn);
user1 = (User) in.readObject();
in.close();
fileIn.close();
}catch(IOException i)
{
i.printStackTrace();
return ;
}catch(ClassNotFoundException c){
System.out.println("User class not found");
c.printStackTrace();
return;
}
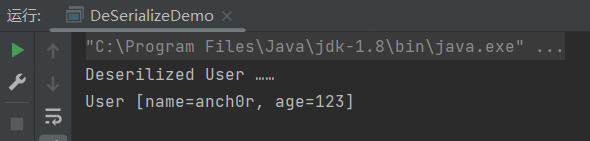
System.out.println("Deserilized User ……");
System.out.println(user1);
}
}
运行结果如下,成功打印出了user1这个实例的信息:
0x02 漏洞产生
看完上面这个简单的序列化和反序列化demo以后,我们确实是掌握如何实现了,但是具体的漏洞点又是怎么产生的呢?对于php,我们知道,它的反序列化会触发一些魔术方法,比如__wakeup,__destruct等等,这些函数中如果有一些命令执行的危险操作,就可能导致漏洞产生。那么java反序列化是通过什么来触发漏洞的?我们可以看看上面这个DeSerializeDemo类,执行反序列化的核心方法就是这个readObject(),对于这个函数方法,它并不是写死在ObjectInputStream类中的,它是支持自定义改写的,包括前面的writeObject方法也是可以改写。所以只要readObject这个方法编写不当,就会造成反序列化漏洞,这就是为啥上一篇文章中我分析到readObject方法那边就说存在反序列化漏洞了。
下面我们只需在User类中改写readObject方法,即可通过反序列化来执行一些命令:
package com.Anchor;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.Serializable;
public class User implements Serializable {
private String name;
private Integer age;
public User() {
}
private User(String name) {
this.name = name;
}
public User(String name, Integer age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
System.out.println(this.getName());
}
public Integer getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "User [name=" + name + ", age=" + age + "]";
}
//改写readObject()方法
private void readObject(ObjectInputStream inputStream) throws IOException,ClassNotFoundException{
//执行默认的readObject()方法
inputStream.defaultReadObject();
//执行命令
Runtime.getRuntime().exec("calc.exe");
}
}
然后和前面一样的,先运行SerializeDemo.java进行序列化,然后运行DeSerializeDemo.java反序列化,成功执行命令,弹出计算器:
0x03 对反序列化的流程分析
我们在DeSerializeDemo的readObject处打上断点,分析反序列化流程(以后用类名#方法形式代指跟进到那个类的方法中):
首先跟进到ObjectInputStream#readObject方法中,
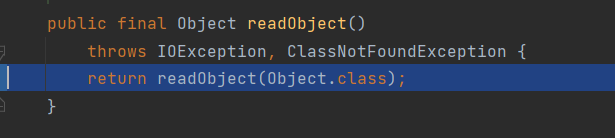
这里会调用readObject的另外一个重载方式:
private final Object readObject(Class<?> type)
throws IOException, ClassNotFoundException
{
if (enableOverride) {
return readObjectOverride();
}
if (! (type == Object.class || type == String.class))
throw new AssertionError("internal error");
// if nested read, passHandle contains handle of enclosing object
int outerHandle = passHandle;
try {
Object obj = readObject0(type, false);
handles.markDependency(outerHandle, passHandle);
ClassNotFoundException ex = handles.lookupException(passHandle);
if (ex != null) {
throw ex;
}
if (depth == 0) {
vlist.doCallbacks();
}
return obj;
} finally {
passHandle = outerHandle;
if (closed && depth == 0) {
clear();
}
}
}
对于第一行的enableOverride,它来自ObjectInputStream构造方法,当调用其无参构造函数时会设定为true,我们这里因为传了fileInputStream,所以为false,并不会进入。接下来可以看到Obj的获取来自readObject0,跟进ObjectInputStream#readObject0看看:
private Object readObject0(boolean unshared) throws IOException {
// 略去源码中对读取模式的检查
// 读取一个字节
byte tc;
while ((tc = bin.peekByte()) == TC_RESET) {
bin.readByte();
handleReset();
}
depth++;
try {
switch (tc) {
case TC_NULL:
return readNull();
case TC_REFERENCE:
return readHandle(unshared);
case TC_CLASS:
return readClass(unshared);
case TC_CLASSDESC:
case TC_PROXYCLASSDESC:
return readClassDesc(unshared);
case TC_STRING:
case TC_LONGSTRING:
return checkResolve(readString(unshared));
case TC_ARRAY:
return checkResolve(readArray(unshared));
case TC_ENUM:
return checkResolve(readEnum(unshared));
case TC_OBJECT:
return checkResolve(readOrdinaryObject(unshared));
case TC_EXCEPTION:
IOException ex = readFatalException();
throw new WriteAbortedException("writing aborted", ex);
case TC_BLOCKDATA:
case TC_BLOCKDATALONG:
// 略
case TC_ENDBLOCKDATA:
// 略
default:
throw new StreamCorruptedException(
String.format("invalid type code: %02X", tc));
}
} finally {
depth--;
bin.setBlockDataMode(oldMode);
}
}
这一部分会先读取一个字节,这个字节是我刚才说的序列化特征aced 0005之后的一个字节,我这里是0x73,十进制的115,之后便会根据这个值进入switch对应的分支:TC_OBJECT,在这之中会继续跟进到ObjectInputStream#readOrdinaryObject函数之中。

private Object readOrdinaryObject(boolean unshared)
throws IOException
{
if (bin.readByte() != TC_OBJECT) {
throw new InternalError();
}
ObjectStreamClass desc = readClassDesc(false);
desc.checkDeserialize();
Class<?> cl = desc.forClass();
if (cl == String.class || cl == Class.class
|| cl == ObjectStreamClass.class) {
throw new InvalidClassException("invalid class descriptor");
}
Object obj;
try {
obj = desc.isInstantiable() ? desc.newInstance() : null;
} catch (Exception ex) {
throw (IOException) new InvalidClassException(
desc.forClass().getName(),
"unable to create instance").initCause(ex);
}
//略
if (desc.isExternalizable()) {
readExternalData((Externalizable) obj, desc);
} else {
readSerialData(obj, desc);
}
//略
return obj;
}
ObjectInputStream#readOrdinaryObject方法中的一些不重要的细节我就直接略过了,主要是看obj的来源。从中可以看到obj的实例化来自于desc,而desc来自ObjectInputStream#readClassDesc,所以先跟进到ObjectInputStream#readClassDesc方法中:
private ObjectStreamClass readClassDesc(boolean unshared)
throws IOException
{
byte tc = bin.peekByte();
ObjectStreamClass descriptor;
switch (tc) {
case TC_NULL:
descriptor = (ObjectStreamClass) readNull();
break;
case TC_REFERENCE:
descriptor = (ObjectStreamClass) readHandle(unshared);
// Should only reference initialized class descriptors
descriptor.checkInitialized();
break;
case TC_PROXYCLASSDESC:
descriptor = readProxyDesc(unshared);
break;
case TC_CLASSDESC:
descriptor = readNonProxyDesc(unshared);
break;
default:
throw new StreamCorruptedException(
String.format("invalid type code: %02X", tc));
}
if (descriptor != null) {
validateDescriptor(descriptor);
}
return descriptor;
}
这里又是一个switch语句,由于我们这里是一个类,所以会进入TC_CLASSDESC,使用readNonProxyDesc获得类的描述信息(字段值之类的)。那就继续跟进到ObjectInputStream#readNonProxyDesc中:
private ObjectStreamClass readNonProxyDesc(boolean unshared)
throws IOException
{
//略
ObjectStreamClass readDesc = null;
try {
readDesc = readClassDescriptor();
} catch (ClassNotFoundException ex) {
throw (IOException) new InvalidClassException(
"failed to read class descriptor").initCause(ex);
}
Class<?> cl = null;
ClassNotFoundException resolveEx = null;
bin.setBlockDataMode(true);
final boolean checksRequired = isCustomSubclass();
try {
if ((cl = resolveClass(readDesc)) == null) {
resolveEx = new ClassNotFoundException("null class");
} else if (checksRequired) {
ReflectUtil.checkPackageAccess(cl);
}
} catch (ClassNotFoundException ex) {
resolveEx = ex;
}
// Call filterCheck on the class before reading anything else
filterCheck(cl, -1);
skipCustomData();
try {
totalObjectRefs++;
depth++;
desc.initNonProxy(readDesc, cl, resolveEx, readClassDesc(false));
if (cl != null) {
// Check that serial filtering has been done on the local class descriptor's superclass,
// in case it does not appear in the stream.
// Find the next super descriptor that has a local class descriptor.
// Descriptors for which there is no local class are ignored.
ObjectStreamClass superLocal = null;
for (ObjectStreamClass sDesc = desc.getSuperDesc(); sDesc != null; sDesc = sDesc.getSuperDesc()) {
if ((superLocal = sDesc.getLocalDesc()) != null) {
break;
}
}
// Scan local descriptor superclasses for a match with the local descriptor of the super found above.
// For each super descriptor before the match, invoke the serial filter on the class.
// The filter is invoked for each class that has not already been filtered
// but would be filtered if the instance had been serialized by this Java runtime.
for (ObjectStreamClass lDesc = desc.getLocalDesc().getSuperDesc();
lDesc != null && lDesc != superLocal;
lDesc = lDesc.getSuperDesc()) {
filterCheck(lDesc.forClass(), -1);
}
}
} finally {
depth--;
}
handles.finish(descHandle);
passHandle = descHandle;
return desc;
}
这里先是使用readClassDescriptor()获得了我们的字段信息,然后使用ObjectInputStream#resolveClass去解析。最后使用initNonProxy把刚刚的字段信息,装载成类描述符,然后返回。这里比较重要的部分是ObjectInputStream#resolveClass()这部分,跳过其他步骤跟进去看看:
protected Class<?> resolveClass(ObjectStreamClass desc)
throws IOException, ClassNotFoundException
{
String name = desc.getName();
try {
return Class.forName(name, false, latestUserDefinedLoader());
} catch (ClassNotFoundException ex) {
Class<?> cl = primClasses.get(name);
if (cl != null) {
return cl;
} else {
throw ex;
}
}
}
看到Class.forName你就知道为什么说resolveClass这块比较重要了,这里利用了我之前文章中讲过的反射来调用我们的类,很多反序列化的防御都是在这里限制了白名单或者黑名单来控制了反序列化。
接下来继续往下跟进,直到回到ObjectInputStream#readOrdinaryObject中,接着就是进入到checkDeserialize()中检查是否可以反序列化:
void checkDeserialize() throws InvalidClassException {
requireInitialized();
if (deserializeEx != null) {
throw deserializeEx.newInvalidClassException();
}
}
完成后我们继续跟进,一直来到ObjectInputStream#readSerialData方法中,代码如下所示:
private void readSerialData(Object obj, ObjectStreamClass desc)
throws IOException
{
ObjectStreamClass.ClassDataSlot[] slots = desc.getClassDataLayout();
for (int i = 0; i < slots.length; i++) {
ObjectStreamClass slotDesc = slots[i].desc;
if (slots[i].hasData) {
if (obj == null || handles.lookupException(passHandle) != null) {
defaultReadFields(null, slotDesc); // skip field values
} else if (slotDesc.hasReadObjectMethod()) { // 判断是否有重写readObject
// 略
bin.setBlockDataMode(true);
slotDesc.invokeReadObject(obj, this); // 调用重写的readObject
} catch (ClassNotFoundException ex) {
// 略
} finally {
// 略
} else {
defaultReadFields(obj, slotDesc); // 这里
}
if (slotDesc.hasWriteObjectData()) {
skipCustomData();
} else {
bin.setBlockDataMode(false);
}
} else {
if (obj != null &&
slotDesc.hasReadObjectNoDataMethod() &&
handles.lookupException(passHandle) == null)
{
slotDesc.invokeReadObjectNoData(obj);
}
}
}
}
这里会先判断是否有重写的readObject,如果有就调用invokeReadObject,其内部反射调用了我们重写的readObject(这时候就触发了我们实验代码中的RCE),没有就调用defaultReadFields进行数据填充(重写readObject中的in.defaultReadObject其实里面也是调用defaultReadFields)。经过这个函数反序列化基本结束,之后readOrdinaryObject返回Obj,readObject中再调用 vlist.doCallbacks()处理回调,结束反序列化流程,返回反序列化成功的Object:
总结一下整个序列化流程:
1.readObject进入readObject0,根据字节选择对应的方法,比如类就会进入readOrdinaryObject
2.readOrdinaryObject中先获取类描述符,进入readClassDesc,根据字节选择对应的类描述符获取方法,其中会调用resolveClass反射实例化我们的目标类
3.readOrdinaryObject再进入readSerialData,根据刚刚的类描述符去填充数据,其中如果目标类重写了readObject则调用,否则就使用默认的填充方法。
0x04 安全隐患
也许你会说,哪有程序员会写上面例子中的那种弱智的代码?确实很少有,但在真实应用中,一些危险操作往往藏得相对隐蔽,不会像我上面这样写的赤裸裸,不过最终的原理都是相同的。
在开发时产生的反序列化漏洞常见的有以下几种情况:
- 重写ObjectInputStream对象的resolveClass方法(这是用来解析传入的类的方法)中的检测可被绕过。
- 使用第三方的类进行黑名单控制。虽然Java的语言严谨性要比PHP强的多,但在大型应用中想要采用黑名单机制禁用掉所有危险的对象几乎是不可能的。因此,如果在审计过程中发现了采用黑名单进行过滤的代码,多半存在一两个‘漏网之鱼’可以利用。并且采取黑名单方式仅仅可能保证此刻的安全,若在后期添加了新的功能,就可能引入了新的漏洞利用方式。所以仅靠黑名单是无法保证序列化过程的安全的。
0x05 小结
本篇只是了解了反序列化以及其具体的实现流程,作为一篇过渡文章,后面进一步学习一些利用链的相关内容。
参考文章:



